
 PhD Student at Universidad Carlos III de Madrid
PhD Student at Universidad Carlos III de MadridHi, I'm Lorena.
I'm finishing my PhD at Universidad Carlos III de Madrid, where my research focuses on making topic models more usable for end users, particularly within the Science, Technology, and Innovation domain.
My work lies at the intersection of NLP, human-computer interaction, and usable software design. I'm passionate about creating language technologies that truly serve people — bridging the gap between technical innovation and real-world usability.
As I complete my PhD (defending on November 28th!), I'm excited to shift my focus toward Clinical NLP, continuing to explore how we can make NLP tools more effective, transparent, and user-centered.
Warning
Problem: The current name of your GitHub Pages repository ("Solution: Please consider renaming the repository to "
http://".
However, if the current repository name is intended, you can ignore this message by removing "{% include widgets/debug_repo_name.html %}" in index.html.
Action required
Problem: The current root path of this site is "baseurl ("_config.yml.
Solution: Please set the
baseurl in _config.yml to "Education
-
Universidad Carlos III de MadridNov. 2021 - Nov. 2025 (Expected)Department of Signal Processing and Communications Engineering
Ph.D. Student in Signal Processing and Communications Engineering- Specialization: Signal and Data Processing
- Dissertation: Topic Analysis Incorporating Expert Knowledge: An Application to Science Analysis
- Advisor: Prof. Jerónimo Arenas-García
-
Universidad Carlos III de MadridSept. 2019 - Oct. 2021Master in Health Engineering
- Thesis: Analysis of Health Text Documents Using Hierarchical Topic Models
- Advisor: Prof. Jerónimo Arenas-García
-
Universidad Carlos III de MadridSept. 2019 - Oct. 2021Master in Telecommunications Engineering
- Thesis: Hierarchical Topic Model Graphical User Interface for Training and Visualization
- Advisor: Prof. Jerónimo Arenas-García
-
Universidad Carlos III de MadridSept. 2014 - Oct. 2018Bachelor in Telecommunication Technologies Engineering
- Thesis: Using Fourier-Motzkin Variable Elimination for MC-SAT Explanations in SMT-RAT
- Advisor: Prof. Dr. Erika Abrahám
Experience
-
Universidad Carlos III de MadridNov. 2021 - PresentNLP Researcher
-
Universidad Carlos III de MadridSept. 2020 - Sept. 2021Research Support Technician
-
 EDC at DeloitteSept. 2019 - Sept. 2020Delivery Analyst
EDC at DeloitteSept. 2019 - Sept. 2020Delivery Analyst -
 RWTH Aachen UniversityNov. 2018 - May. 2019Student Helper in Knowledge-Based Systems Group
RWTH Aachen UniversityNov. 2018 - May. 2019Student Helper in Knowledge-Based Systems Group -
 DTS-Movistar+Jul. 2017 - Sept. 2017Testing Technician (Summer Intern)
DTS-Movistar+Jul. 2017 - Sept. 2017Testing Technician (Summer Intern) -
Universidad Carlos III de MadridJul. 2016 - Jul. 2017Lab Technician in Telematics Department
Academic Experience
-
 University of MarylandMar. 2024 - Jul. 2024Visiting Scholar
University of MarylandMar. 2024 - Jul. 2024Visiting Scholar- Supervisor: Prof. Jordan Boyd-Graber
-
 ETH ZürichMar. 2025 - Apr. 2025Visiting Scholar
ETH ZürichMar. 2025 - Apr. 2025Visiting Scholar- Supervisor: Dr. Alexander Hoyle
-
RWTH Aachen UniversityOct. 2017 - Aug. 2018Erasmus Student
Research Projects
-
NEXTPROCUREMENT: Open Harmonized and Enriched Public Procurement PlatformSept. 2022 - Mar. 2023, Apr. 2024 - Mar. 2025European CommissionMain Researcher: Jerónimo Arenas García
-
Massive Text Processing and AI for the Management of Research and Training at the UniversityMar. 2023 - Apr. 2024TED2021-132366B-I00Main Researcher: Jerónimo Arenas García
-
INTELCOMP: A Competitive Intelligence Cloud/HPC Platform for AI-based STI Policy MakingSept. 2022 - Mar. 2023European CommissionMain Researcher: Jerónimo Arenas García
-
ERA4TB: European Regimen Accelerator for TuberculosisSept. 2022 - Mar. 2023European CommissionMain Researcher: Juan José Vaquero López
Teaching & Service
-
Natural Language ProcessingWinter 2022, Winter 2023, Winter 2024Co-instructor
-
Modern Theory of Detection and EstimationWinter 2022Co-instructor
-
Data ProcessingWinter 2023Co-instructor
News
Selected Publications (view all )
Discrepancy Detection at the Data Level: Toward Consistent Multilingual Question Answering
Lorena Calvo-Bartolomé, Valérie Aldana, Karla Cantarero, Alonso Madroñal de Mesa, Jerónimo Arenas-García, Jordan Lee Boyd-Graber
EMNLP 2025
Multilingual question answering (QA) systems must ensure factual consistency across languages, especially for objective queries such as What is jaundice?, while also accounting for cultural variation in subjective responses. We propose MIND, a user-in-the-loop fact-checking pipeline to detect factual and cultural discrepancies in multilingual QA knowledge bases. MIND highlights divergent answers to culturally sensitive questions (e.g., Who assists in childbirth?) that vary by region and context. We evaluate MIND on a bilingual QA system in the maternal and infant health domain and release a dataset of bilingual questions annotated for factual and cultural inconsistencies. We further test MIND on datasets from other domains to assess generalization. In all cases, MIND reliably identifies inconsistencies, supporting the development of more culturally aware and factually consistent QA systems.
Discrepancy Detection at the Data Level: Toward Consistent Multilingual Question Answering
Lorena Calvo-Bartolomé, Valérie Aldana, Karla Cantarero, Alonso Madroñal de Mesa, Jerónimo Arenas-García, Jordan Lee Boyd-Graber
EMNLP 2025
Multilingual question answering (QA) systems must ensure factual consistency across languages, especially for objective queries such as What is jaundice?, while also accounting for cultural variation in subjective responses. We propose MIND, a user-in-the-loop fact-checking pipeline to detect factual and cultural discrepancies in multilingual QA knowledge bases. MIND highlights divergent answers to culturally sensitive questions (e.g., Who assists in childbirth?) that vary by region and context. We evaluate MIND on a bilingual QA system in the maternal and infant health domain and release a dataset of bilingual questions annotated for factual and cultural inconsistencies. We further test MIND on datasets from other domains to assess generalization. In all cases, MIND reliably identifies inconsistencies, supporting the development of more culturally aware and factually consistent QA systems.
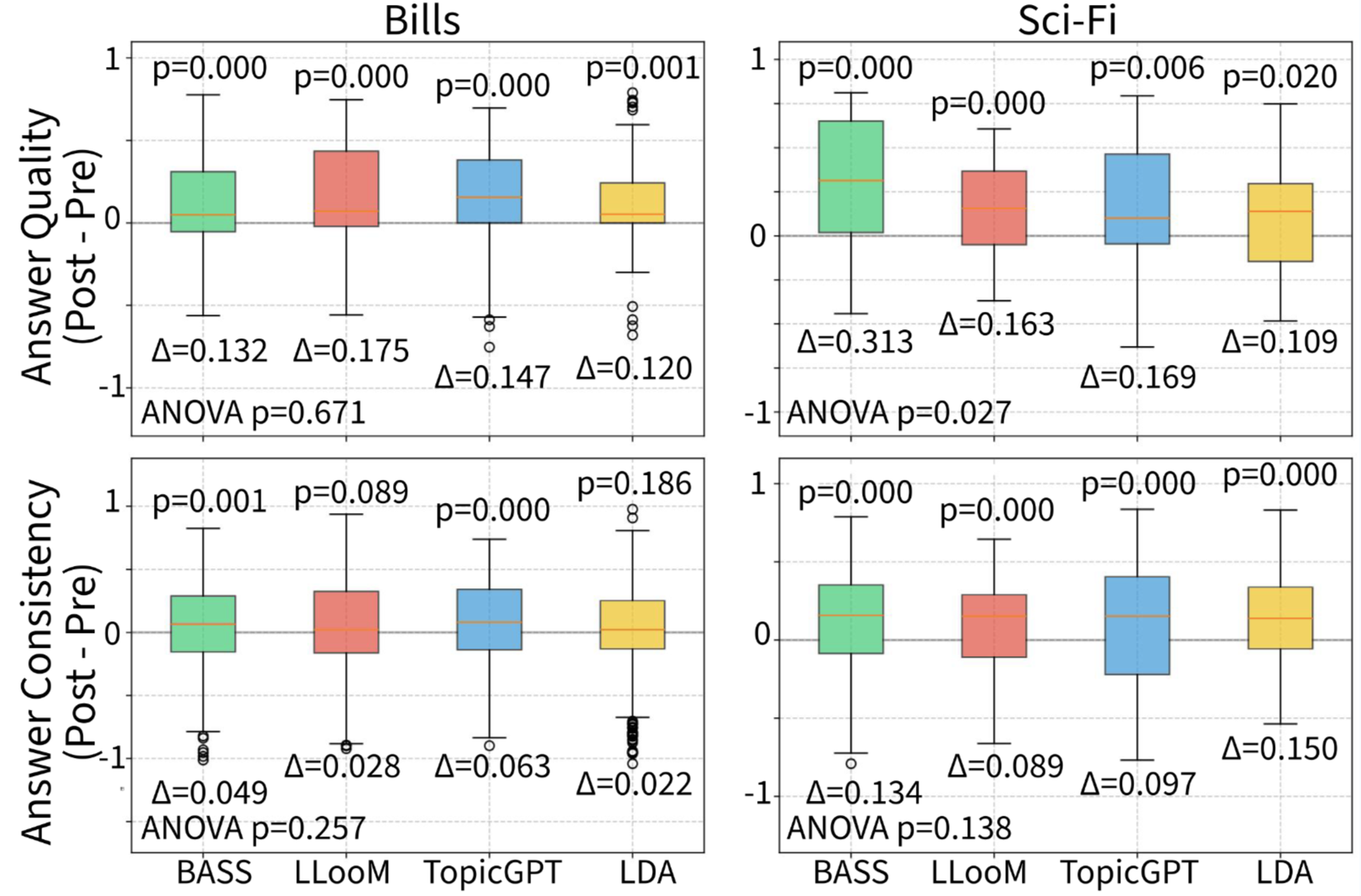
Large Language Models Struggle to Describe the Haystack without Human Help: A Social Science-Inspired Evaluation of Large Research Language Models
Zongxia Li, Lorena Calvo-Bartolomé, Alexander Hoyle, Paiheng Xu, Daniel Stephens, Alden Dima, Juan Francisco Fung, Jordan Lee Boyd-Graber
ACL 2025
A common use of NLP is to facilitate the understanding of large document collections, with models based on Large Language Models (LLMs) replacing probabilistic topic models. Yet the effectiveness of LLM-based approaches in real-world applications remains under explored. This study measures the knowledge users acquire with topic models—including traditional, unsupervised and supervised LLM- based approaches—on two datasets. While LLM-based methods generate more human- readable topics and show higher average win probabilities than traditional models for data exploration, they produce overly generic topics for domain-specific datasets that do not easily allow users to learn much about the documents. Adding human supervision to LLM-based topic models improves data exploration by addressing hallucination and genericity but requires more human efforts. In contrast, traditional models like Latent Dirichlet Allocation (LDA) remain effective for exploration but are less user-friendly. This paper provides best practices—there is no one right model, the choice of models is situation-specific—and suggests potential improvements for scalable LLM- based topic models.
Large Language Models Struggle to Describe the Haystack without Human Help: A Social Science-Inspired Evaluation of Large Research Language Models
Zongxia Li, Lorena Calvo-Bartolomé, Alexander Hoyle, Paiheng Xu, Daniel Stephens, Alden Dima, Juan Francisco Fung, Jordan Lee Boyd-Graber
ACL 2025
A common use of NLP is to facilitate the understanding of large document collections, with models based on Large Language Models (LLMs) replacing probabilistic topic models. Yet the effectiveness of LLM-based approaches in real-world applications remains under explored. This study measures the knowledge users acquire with topic models—including traditional, unsupervised and supervised LLM- based approaches—on two datasets. While LLM-based methods generate more human- readable topics and show higher average win probabilities than traditional models for data exploration, they produce overly generic topics for domain-specific datasets that do not easily allow users to learn much about the documents. Adding human supervision to LLM-based topic models improves data exploration by addressing hallucination and genericity but requires more human efforts. In contrast, traditional models like Latent Dirichlet Allocation (LDA) remain effective for exploration but are less user-friendly. This paper provides best practices—there is no one right model, the choice of models is situation-specific—and suggests potential improvements for scalable LLM- based topic models.
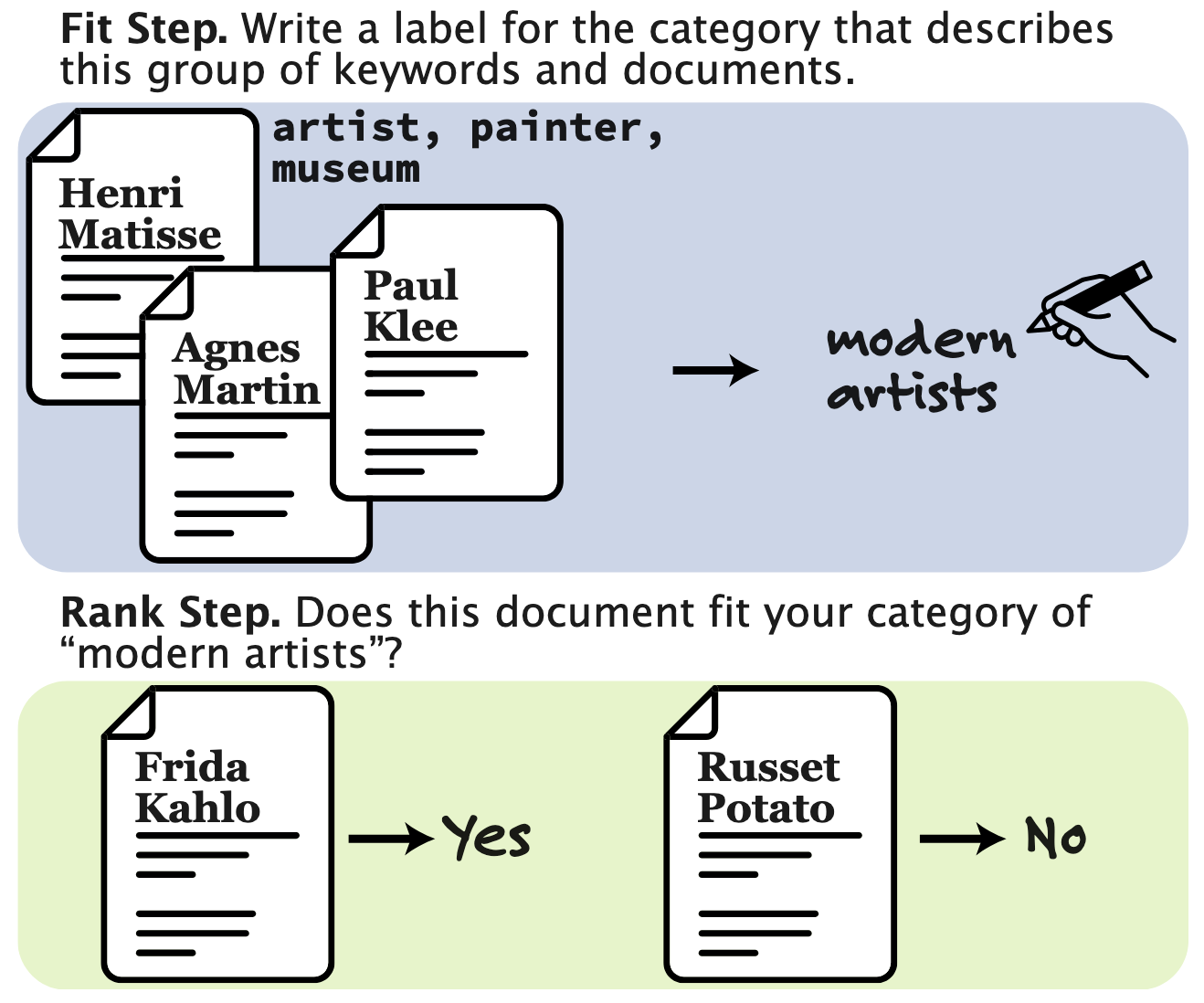
ProxAnn: Use-Oriented Evaluations of Topic Models and Document Clustering
Alexander Hoyle, Lorena Calvo-Bartolomé, Jordan Boyd-Graber, Philip Resnik
ACL 2025
Topic model and document-clustering evaluations either use automated metrics that align poorly with human preferences or require expert labels that are intractable to scale. We design a scalable human evaluation protocol and a corresponding automated approximation that reflect practitioners' real-world usage of models. Annotators -- or an LLM-based proxy -- review text items assigned to a topic or cluster, infer a category for the group, then apply that category to other documents. Using this protocol, we collect extensive crowdworker annotations of outputs from a diverse set of topic models on two datasets. We then use these annotations to validate automated proxies, finding that the best LLM proxies are statistically indistinguishable from a human annotator and can therefore serve as a reasonable substitute in automated evaluations. Package, web interface, and data are at https://github.com/ahoho/proxann
ProxAnn: Use-Oriented Evaluations of Topic Models and Document Clustering
Alexander Hoyle, Lorena Calvo-Bartolomé, Jordan Boyd-Graber, Philip Resnik
ACL 2025
Topic model and document-clustering evaluations either use automated metrics that align poorly with human preferences or require expert labels that are intractable to scale. We design a scalable human evaluation protocol and a corresponding automated approximation that reflect practitioners' real-world usage of models. Annotators -- or an LLM-based proxy -- review text items assigned to a topic or cluster, infer a category for the group, then apply that category to other documents. Using this protocol, we collect extensive crowdworker annotations of outputs from a diverse set of topic models on two datasets. We then use these annotations to validate automated proxies, finding that the best LLM proxies are statistically indistinguishable from a human annotator and can therefore serve as a reasonable substitute in automated evaluations. Package, web interface, and data are at https://github.com/ahoho/proxann
CASE: Large Scale Topic Exploitation for Decision Support Systems
Lorena Calvo-Bartolomé, Jerónimo Arenas-García, David Pérez-Fernández
COLING 2025
In recent years, there has been growing interest in using NLP tools for decision support systems, particularly in Science, Technology, and Innovation (STI). Among these, topic modeling has been widely used for analyzing large document collections, such as scientific articles, research projects, or patents, yet its integration into decision-making systems remains limited. This paper introduces CASE, a tool for exploiting topic information for semantic analysis of large corpora. The core of CASE is a Solr engine with a customized indexing strategy to represent information from Bayesian and Neural topic models that allow efficient topic-enriched searches. Through ad hoc plug-ins, CASE enables topic inference on new texts and semantic search. We demonstrate the versatility and scalability of CASE through two use cases: the calculation of aggregated STI indicators and the implementation of a web service to help evaluate research projects.
CASE: Large Scale Topic Exploitation for Decision Support Systems
Lorena Calvo-Bartolomé, Jerónimo Arenas-García, David Pérez-Fernández
COLING 2025
In recent years, there has been growing interest in using NLP tools for decision support systems, particularly in Science, Technology, and Innovation (STI). Among these, topic modeling has been widely used for analyzing large document collections, such as scientific articles, research projects, or patents, yet its integration into decision-making systems remains limited. This paper introduces CASE, a tool for exploiting topic information for semantic analysis of large corpora. The core of CASE is a Solr engine with a customized indexing strategy to represent information from Bayesian and Neural topic models that allow efficient topic-enriched searches. Through ad hoc plug-ins, CASE enables topic inference on new texts and semantic search. We demonstrate the versatility and scalability of CASE through two use cases: the calculation of aggregated STI indicators and the implementation of a web service to help evaluate research projects.