2025
Topic models for decision-support systems, Part II: Expert-in-the-loop hierarchical topic models
Lorena Calvo-Bartolomé, Jerónimo Arenas-García
Engineering Applications of Artificial Intelligence 2025
Topic modeling has been extensively used across disciplines to extract knowledge from text collections for policy design, implementation, and monitoring. However, flat topic models are limited in their ability to group overly broad topics with more specific ones. Hierarchical topic models (\htm{}) address this limitation by offering thematic analysis at different granularity levels, but existing \htm{}s rely on complex implementations, complicating hyperparameter tuning and domain expert-guided topic curation. This paper introduces two novel algorithms for hierarchical topic modeling: \ws{} (\htm{} with word selection) and \ds{} (\htm{} with document selection). These algorithms adopt an expert-in-the-loop approach, allowing domain experts to refine topic hierarchies by identifying subtopics for further partitioning. They are model-agnostic, compatible with both Neural and Bayesian-based topic models, and simplify hyperparameter tuning to match the ease of flat topic models. Both methods are integrated into a toolkit developed for IntelComp, a European project focused on topic model training and exploitation. Experiments on three datasets of scientific papers demonstrate the effectiveness of the proposed algorithms through quantitative evaluations using automatic metrics and qualitative assessments via human evaluation, and comparisons against existing hierarchical topic models from the literature.
Topic models for decision-support systems, Part II: Expert-in-the-loop hierarchical topic models
Lorena Calvo-Bartolomé, Jerónimo Arenas-García
Engineering Applications of Artificial Intelligence 2025
Topic modeling has been extensively used across disciplines to extract knowledge from text collections for policy design, implementation, and monitoring. However, flat topic models are limited in their ability to group overly broad topics with more specific ones. Hierarchical topic models (\htm{}) address this limitation by offering thematic analysis at different granularity levels, but existing \htm{}s rely on complex implementations, complicating hyperparameter tuning and domain expert-guided topic curation. This paper introduces two novel algorithms for hierarchical topic modeling: \ws{} (\htm{} with word selection) and \ds{} (\htm{} with document selection). These algorithms adopt an expert-in-the-loop approach, allowing domain experts to refine topic hierarchies by identifying subtopics for further partitioning. They are model-agnostic, compatible with both Neural and Bayesian-based topic models, and simplify hyperparameter tuning to match the ease of flat topic models. Both methods are integrated into a toolkit developed for IntelComp, a European project focused on topic model training and exploitation. Experiments on three datasets of scientific papers demonstrate the effectiveness of the proposed algorithms through quantitative evaluations using automatic metrics and qualitative assessments via human evaluation, and comparisons against existing hierarchical topic models from the literature.
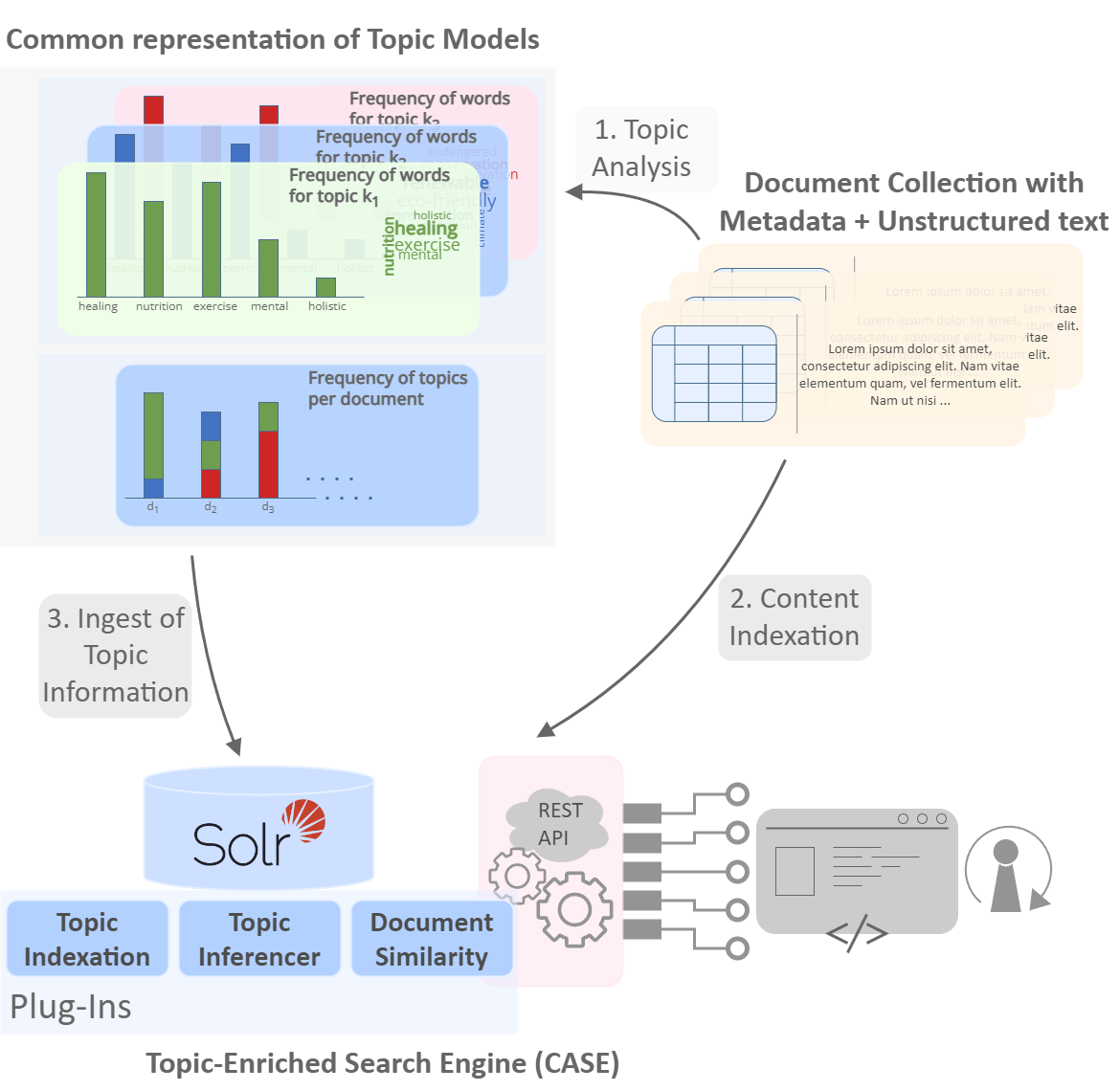
Topic models for decision-support systems. Part I: Training, representation and exploitation of topic models
Lorena Calvo-Bartolomé, Diamantis Tziotzios, Saúl Blanco-Fortes, David Pérez-Fernández, Jerónimo Arenas-García
Engineering Applications of Artificial Intelligence 2025
Analyzing document collections in Science, Technology, and Innovation (STI) is essential for informed policy-making. Advances in topic modeling offer powerful tools to uncover key themes within large, heterogeneous STI datasets that can inform decision-making. However, challenges such as aligning model outputs with expert knowledge, determining the desired topic granularity, and addressing model variability, limit their widespread adoption. This paper presents the Topic Analysis and Search Engine (tase), a platform developed within the European IntelComp project to address these limitations. tase combines Bayesian and Neural topic modeling techniques within a unified framework that incorporates an expert-in-the-loop approach for training and curating models. This framework is further enhanced with a Solr-based exploitation tool, featuring an innovative indexing method and a novel criterion for document retrieval. These features enable efficient semantic similarity calculations and seamless integration into decision-support systems. We demonstrate tase’s scalability and effectiveness through two real-world STI use cases, highlighting its potential for broader applications. The software is freely available as open-source under the MIT license.
Topic models for decision-support systems. Part I: Training, representation and exploitation of topic models
Lorena Calvo-Bartolomé, Diamantis Tziotzios, Saúl Blanco-Fortes, David Pérez-Fernández, Jerónimo Arenas-García
Engineering Applications of Artificial Intelligence 2025
Analyzing document collections in Science, Technology, and Innovation (STI) is essential for informed policy-making. Advances in topic modeling offer powerful tools to uncover key themes within large, heterogeneous STI datasets that can inform decision-making. However, challenges such as aligning model outputs with expert knowledge, determining the desired topic granularity, and addressing model variability, limit their widespread adoption. This paper presents the Topic Analysis and Search Engine (tase), a platform developed within the European IntelComp project to address these limitations. tase combines Bayesian and Neural topic modeling techniques within a unified framework that incorporates an expert-in-the-loop approach for training and curating models. This framework is further enhanced with a Solr-based exploitation tool, featuring an innovative indexing method and a novel criterion for document retrieval. These features enable efficient semantic similarity calculations and seamless integration into decision-support systems. We demonstrate tase’s scalability and effectiveness through two real-world STI use cases, highlighting its potential for broader applications. The software is freely available as open-source under the MIT license.
Discrepancy Detection at the Data Level: Toward Consistent Multilingual Question Answering
Lorena Calvo-Bartolomé, Valérie Aldana, Karla Cantarero, Alonso Madroñal de Mesa, Jerónimo Arenas-García, Jordan Lee Boyd-Graber
EMNLP 2025
Multilingual question answering (QA) systems must ensure factual consistency across languages, especially for objective queries such as What is jaundice?, while also accounting for cultural variation in subjective responses. We propose MIND, a user-in-the-loop fact-checking pipeline to detect factual and cultural discrepancies in multilingual QA knowledge bases. MIND highlights divergent answers to culturally sensitive questions (e.g., Who assists in childbirth?) that vary by region and context. We evaluate MIND on a bilingual QA system in the maternal and infant health domain and release a dataset of bilingual questions annotated for factual and cultural inconsistencies. We further test MIND on datasets from other domains to assess generalization. In all cases, MIND reliably identifies inconsistencies, supporting the development of more culturally aware and factually consistent QA systems.
Discrepancy Detection at the Data Level: Toward Consistent Multilingual Question Answering
Lorena Calvo-Bartolomé, Valérie Aldana, Karla Cantarero, Alonso Madroñal de Mesa, Jerónimo Arenas-García, Jordan Lee Boyd-Graber
EMNLP 2025
Multilingual question answering (QA) systems must ensure factual consistency across languages, especially for objective queries such as What is jaundice?, while also accounting for cultural variation in subjective responses. We propose MIND, a user-in-the-loop fact-checking pipeline to detect factual and cultural discrepancies in multilingual QA knowledge bases. MIND highlights divergent answers to culturally sensitive questions (e.g., Who assists in childbirth?) that vary by region and context. We evaluate MIND on a bilingual QA system in the maternal and infant health domain and release a dataset of bilingual questions annotated for factual and cultural inconsistencies. We further test MIND on datasets from other domains to assess generalization. In all cases, MIND reliably identifies inconsistencies, supporting the development of more culturally aware and factually consistent QA systems.
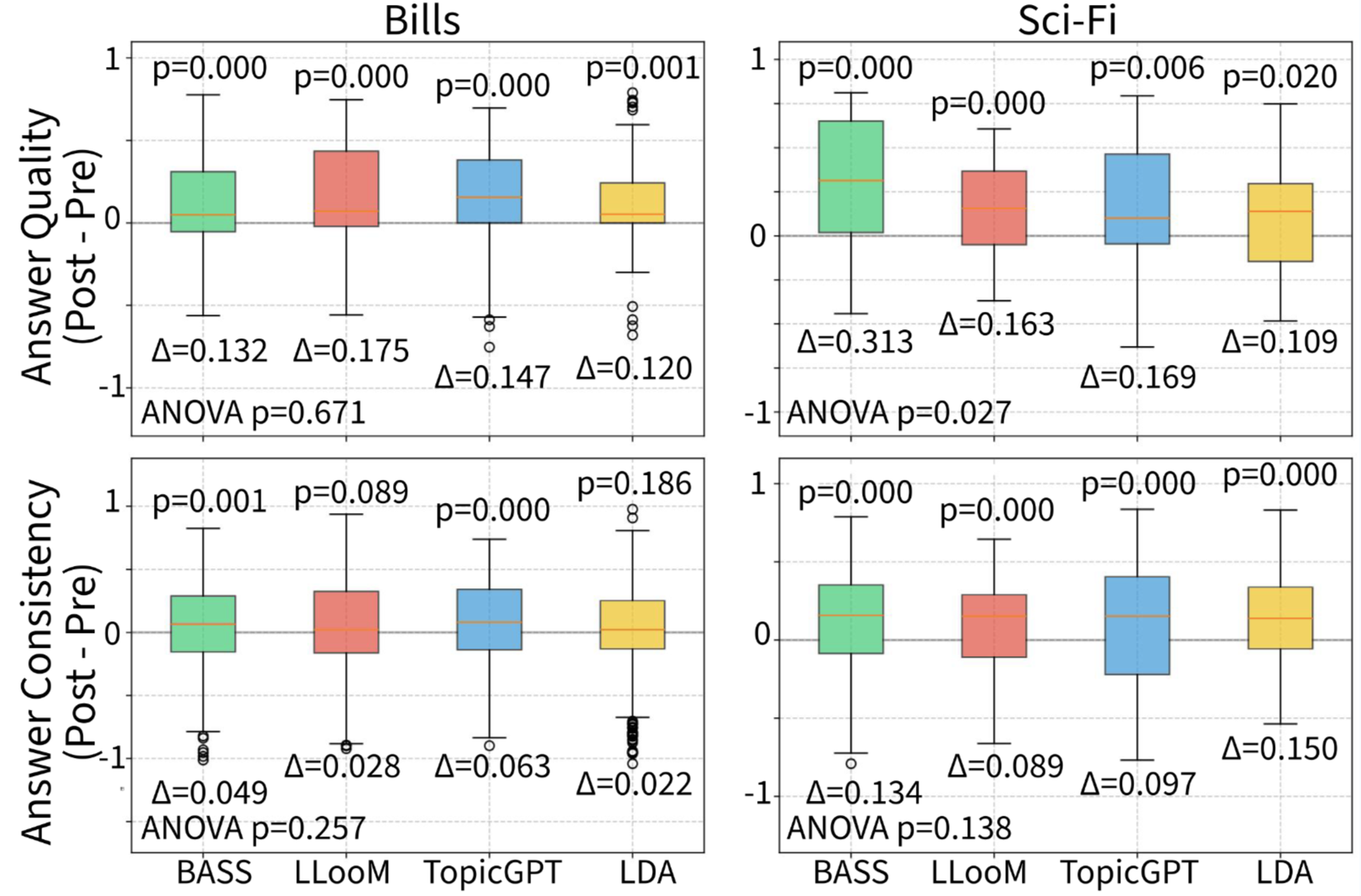
Large Language Models Struggle to Describe the Haystack without Human Help: A Social Science-Inspired Evaluation of Large Research Language Models
Zongxia Li, Lorena Calvo-Bartolomé, Alexander Hoyle, Paiheng Xu, Daniel Stephens, Alden Dima, Juan Francisco Fung, Jordan Lee Boyd-Graber
ACL 2025
A common use of NLP is to facilitate the understanding of large document collections, with models based on Large Language Models (LLMs) replacing probabilistic topic models. Yet the effectiveness of LLM-based approaches in real-world applications remains under explored. This study measures the knowledge users acquire with topic models—including traditional, unsupervised and supervised LLM- based approaches—on two datasets. While LLM-based methods generate more human- readable topics and show higher average win probabilities than traditional models for data exploration, they produce overly generic topics for domain-specific datasets that do not easily allow users to learn much about the documents. Adding human supervision to LLM-based topic models improves data exploration by addressing hallucination and genericity but requires more human efforts. In contrast, traditional models like Latent Dirichlet Allocation (LDA) remain effective for exploration but are less user-friendly. This paper provides best practices—there is no one right model, the choice of models is situation-specific—and suggests potential improvements for scalable LLM- based topic models.
Large Language Models Struggle to Describe the Haystack without Human Help: A Social Science-Inspired Evaluation of Large Research Language Models
Zongxia Li, Lorena Calvo-Bartolomé, Alexander Hoyle, Paiheng Xu, Daniel Stephens, Alden Dima, Juan Francisco Fung, Jordan Lee Boyd-Graber
ACL 2025
A common use of NLP is to facilitate the understanding of large document collections, with models based on Large Language Models (LLMs) replacing probabilistic topic models. Yet the effectiveness of LLM-based approaches in real-world applications remains under explored. This study measures the knowledge users acquire with topic models—including traditional, unsupervised and supervised LLM- based approaches—on two datasets. While LLM-based methods generate more human- readable topics and show higher average win probabilities than traditional models for data exploration, they produce overly generic topics for domain-specific datasets that do not easily allow users to learn much about the documents. Adding human supervision to LLM-based topic models improves data exploration by addressing hallucination and genericity but requires more human efforts. In contrast, traditional models like Latent Dirichlet Allocation (LDA) remain effective for exploration but are less user-friendly. This paper provides best practices—there is no one right model, the choice of models is situation-specific—and suggests potential improvements for scalable LLM- based topic models.
ProxAnn: Use-Oriented Evaluations of Topic Models and Document Clustering
Alexander Hoyle, Lorena Calvo-Bartolomé, Jordan Boyd-Graber, Philip Resnik
ACL 2025
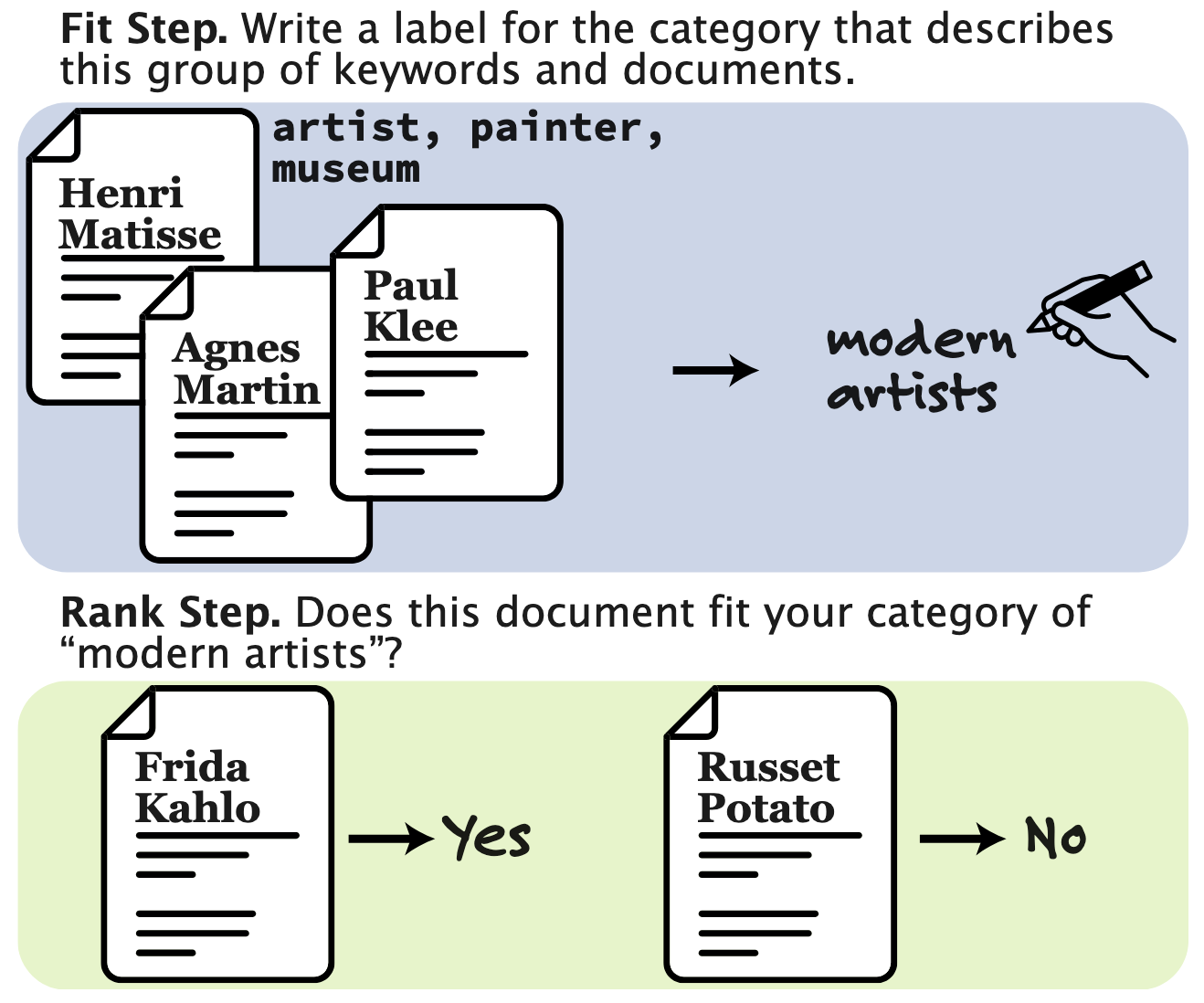
Topic model and document-clustering evaluations either use automated metrics that align poorly with human preferences or require expert labels that are intractable to scale. We design a scalable human evaluation protocol and a corresponding automated approximation that reflect practitioners' real-world usage of models. Annotators -- or an LLM-based proxy -- review text items assigned to a topic or cluster, infer a category for the group, then apply that category to other documents. Using this protocol, we collect extensive crowdworker annotations of outputs from a diverse set of topic models on two datasets. We then use these annotations to validate automated proxies, finding that the best LLM proxies are statistically indistinguishable from a human annotator and can therefore serve as a reasonable substitute in automated evaluations. Package, web interface, and data are at https://github.com/ahoho/proxann
ProxAnn: Use-Oriented Evaluations of Topic Models and Document Clustering
Alexander Hoyle, Lorena Calvo-Bartolomé, Jordan Boyd-Graber, Philip Resnik
ACL 2025
Topic model and document-clustering evaluations either use automated metrics that align poorly with human preferences or require expert labels that are intractable to scale. We design a scalable human evaluation protocol and a corresponding automated approximation that reflect practitioners' real-world usage of models. Annotators -- or an LLM-based proxy -- review text items assigned to a topic or cluster, infer a category for the group, then apply that category to other documents. Using this protocol, we collect extensive crowdworker annotations of outputs from a diverse set of topic models on two datasets. We then use these annotations to validate automated proxies, finding that the best LLM proxies are statistically indistinguishable from a human annotator and can therefore serve as a reasonable substitute in automated evaluations. Package, web interface, and data are at https://github.com/ahoho/proxann
2024
CASE: Large Scale Topic Exploitation for Decision Support Systems
Lorena Calvo-Bartolomé, Jerónimo Arenas-García, David Pérez-Fernández
COLING 2025
In recent years, there has been growing interest in using NLP tools for decision support systems, particularly in Science, Technology, and Innovation (STI). Among these, topic modeling has been widely used for analyzing large document collections, such as scientific articles, research projects, or patents, yet its integration into decision-making systems remains limited. This paper introduces CASE, a tool for exploiting topic information for semantic analysis of large corpora. The core of CASE is a Solr engine with a customized indexing strategy to represent information from Bayesian and Neural topic models that allow efficient topic-enriched searches. Through ad hoc plug-ins, CASE enables topic inference on new texts and semantic search. We demonstrate the versatility and scalability of CASE through two use cases: the calculation of aggregated STI indicators and the implementation of a web service to help evaluate research projects.
CASE: Large Scale Topic Exploitation for Decision Support Systems
Lorena Calvo-Bartolomé, Jerónimo Arenas-García, David Pérez-Fernández
COLING 2025
In recent years, there has been growing interest in using NLP tools for decision support systems, particularly in Science, Technology, and Innovation (STI). Among these, topic modeling has been widely used for analyzing large document collections, such as scientific articles, research projects, or patents, yet its integration into decision-making systems remains limited. This paper introduces CASE, a tool for exploiting topic information for semantic analysis of large corpora. The core of CASE is a Solr engine with a customized indexing strategy to represent information from Bayesian and Neural topic models that allow efficient topic-enriched searches. Through ad hoc plug-ins, CASE enables topic inference on new texts and semantic search. We demonstrate the versatility and scalability of CASE through two use cases: the calculation of aggregated STI indicators and the implementation of a web service to help evaluate research projects.
2023
ITMT: Interactive Topic Model Trainer
Lorena Calvo-Bartolomé, Jose Antonio Espinosa Melchor, Jerónimo Arenas-García
EACL 2023
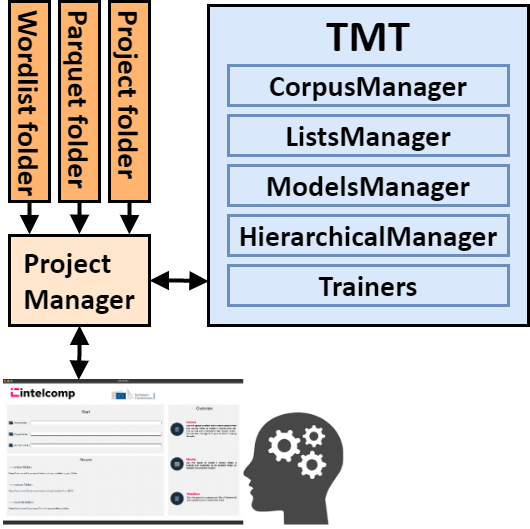
Topic Modeling is a commonly used technique for analyzing unstructured data in various fields, but achieving accurate results and useful models can be challenging, especially for domain experts who lack the knowledge needed to optimize the parameters required by this natural language processing technique. From this perspective, we introduce an Interactive Topic Model Trainer (ITMT) developed within the EU-funded project IntelComp. ITMT is a user-in-the-loop topic modeling tool presented with a graphical user interface that allows the training and curation of different state-of-the-art topic extraction libraries, including some recent neural-based methods, oriented toward the usage by domain experts. This paper reviews ITMT's functionalities and key implementation aspects in this paper, including a comparison with other tools for topic modeling analysis.
ITMT: Interactive Topic Model Trainer
Lorena Calvo-Bartolomé, Jose Antonio Espinosa Melchor, Jerónimo Arenas-García
EACL 2023
Topic Modeling is a commonly used technique for analyzing unstructured data in various fields, but achieving accurate results and useful models can be challenging, especially for domain experts who lack the knowledge needed to optimize the parameters required by this natural language processing technique. From this perspective, we introduce an Interactive Topic Model Trainer (ITMT) developed within the EU-funded project IntelComp. ITMT is a user-in-the-loop topic modeling tool presented with a graphical user interface that allows the training and curation of different state-of-the-art topic extraction libraries, including some recent neural-based methods, oriented toward the usage by domain experts. This paper reviews ITMT's functionalities and key implementation aspects in this paper, including a comparison with other tools for topic modeling analysis.